
Traditional risk models have long been treated as reliable workhorses of financial risk management, and for decades, logistic regression, scorecards, and rule-based systems served their purpose reasonably well. But the financial landscape has become considerably more complex, driven by faster credit cycles, interconnected markets, and the sheer volume of data that institutions must process every day. The assumption that classical models still handle risk adequately is one of the costlier misconceptions in the industry today. Machine learning (ML) offers something fundamentally different: the ability to learn [non-linear risk patterns] from massive, multi-dimensional datasets and generate adaptive, real-time predictions rather than rely on backward-looking rules.
Table of Contents
- How machine learning redefines risk assessment
- Predictive power and performance: ML versus classical models
- Human expertise, augmentation, and operational risk management
- Explainability, validation, and governance: Regulatory expectations
- Limitations, edge cases, and practical deployment tips
- Why risk managers should demand more than accuracy: The real value of machine learning
- Take your risk assessment to the next level with AI-powered solutions
- Frequently asked questions
Key Takeaways
| Point | Details |
|---|---|
| ML finds hidden risk patterns | Machine learning can reveal complex risk interactions and adapt rapidly to changing conditions that traditional models miss. |
| Performance outpaces classic models | Empirical evidence shows ML offers superior predictive accuracy and stress resilience in risk forecasting. |
| Human expertise remains essential | ML augments rather than replaces expert judgment, improving consistency and scalability in risk assessments. |
| Regulatory compliance is critical | Risk managers must ensure ML models are explainable, validated, and independently audited for regulatory approval. |
| Beware edge cases and bias | Financial institutions should monitor model stability, bias, and explainability to guard against deployment risk. |
How machine learning redefines risk assessment
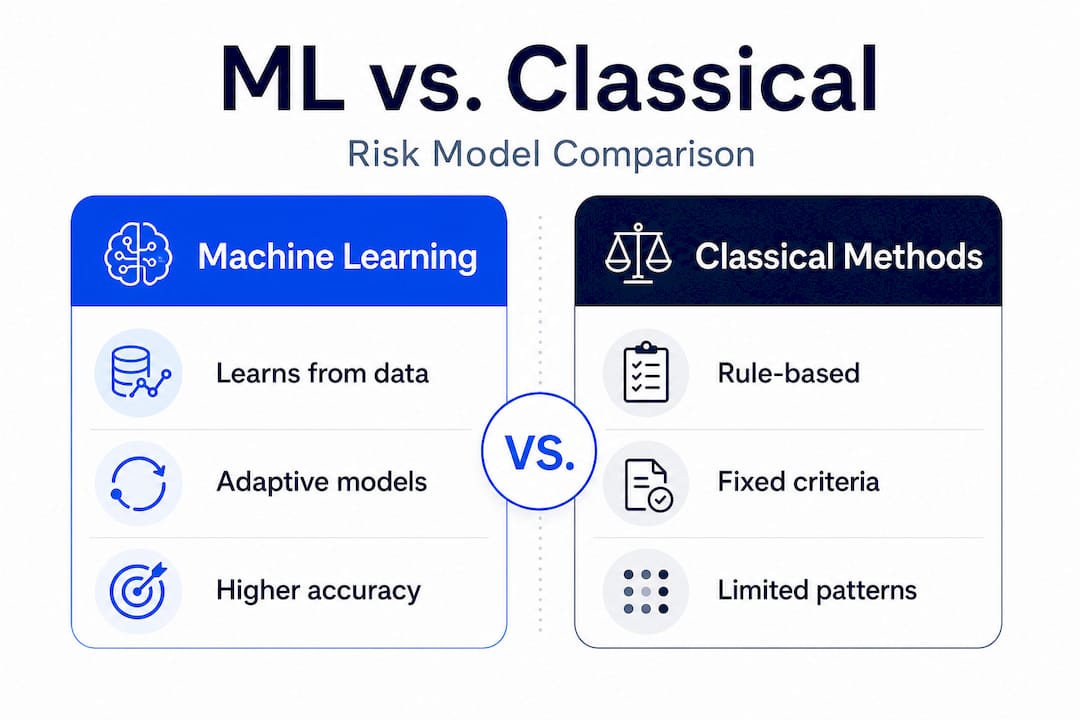
Having set the stage for why risk managers need more robust tools, let's look specifically at what ML makes possible. The core advantage of machine learning in risk assessment is its capacity to detect patterns that human analysts and classical models routinely miss. Traditional methods rely on linear relationships between variables, meaning they perform well when the data behaves predictably, but fall short when credit conditions shift, borrower behavior changes, or macroeconomic stress creates non-linear feedback loops across a portfolio.
ML models, by contrast, learn directly from data. They can process structured inputs like financial ratios and payment histories alongside unstructured signals like transaction patterns or economic indicators, and they update those learned relationships as new data arrives. This is what AI-driven risk management is built on: continuous learning, not periodic recalibration. According to Wall Street Prep, machine learning improves risk assessment accuracy by enabling predictive analytics, pattern recognition, and real-time risk monitoring that static models simply cannot replicate.
Beyond pattern detection, ML also reduces human bias in the underwriting and risk classification process. When analysts apply manual judgment repeatedly across hundreds of loan files or counterparty assessments, inconsistencies inevitably emerge. ML standardizes the decision logic, applies it uniformly, and flags exceptions for human review rather than absorbing them silently into flawed conclusions. Research supported by the Bank for International Settlements found that tree-based ML methods outperform classical time-series approaches in forecasting the full distribution of future market stress, including tail behavior, which is precisely where financial institutions need the most precision.
Here is a snapshot of how ML-based approaches compare to classical methods across key dimensions:
| Dimension | Classical models | ML-based models |
|---|---|---|
| Pattern recognition | Linear only | Linear and non-linear |
| Data types processed | Structured only | Structured and unstructured |
| Update frequency | Periodic recalibration | Continuous or near real-time |
| Tail risk forecasting | Limited | Stronger, especially tree-based |
| Bias reduction | Relies on analyst discipline | Standardized, auditable logic |
Key capabilities ML brings to risk assessment methods that classical approaches lack include:
- Detection of complex, non-linear interactions between risk drivers
- Real-time monitoring and prediction updating as portfolio conditions change
- Adaptive modeling that adjusts when credit or market dynamics shift
- Consistent application of risk logic across large volumes of exposures
These capabilities are not theoretical. They translate directly into more accurate early warning systems, better portfolio segmentation, and more defensible credit decisions under regulatory scrutiny.
Predictive power and performance: ML versus classical models
Now that you see what ML models can uncover, let's compare actual performance and understand their predictive edge. The most compelling evidence for ML adoption in risk assessment comes from empirical performance benchmarks rather than vendor claims. When researchers at the BIS compared tree-based ML models against autoregressive benchmarks for market stress forecasting, they found that random forests achieved up to 27% lower quantile loss at forecast horizons of 3 to 12 months. That is a material improvement in tail risk estimation, exactly the territory where financial institutions are most vulnerable.

Credit risk classification results are equally persuasive. A peer-reviewed Springer Nature study tested logistic regression, decision trees, XGBoost, and a multilayer perceptron against each other, and [XGBoost delivered] the best area under the curve (AUC) score of 0.89 under normal conditions. More significantly, XGBoost maintained an AUC of 0.83 under stress-test simulations, while logistic regression dropped to 0.68. That gap in resilience matters enormously when macroeconomic conditions deteriorate.
For ML credit assessment programs to deliver this level of performance, institutions should evaluate models across multiple dimensions, not just baseline accuracy:
- Quantile loss at tail horizons (3 to 12 months forward)
- AUC performance under both baseline and stress scenarios
- Stability of variable importance rankings across market regimes
- Consistency of predictions across demographically similar borrower segments
Pro Tip: When evaluating ML models for credit or market risk, always request stress-test performance metrics alongside baseline accuracy scores. A model that looks excellent in calm markets but degrades significantly under adverse conditions offers far less value to your institution than its headline AUC suggests.
The takeaway is not simply that ML models score higher on accuracy metrics. It is that they retain predictive integrity under conditions that break classical models. That resilience has direct implications for capital planning, stress testing, and regulatory submissions where the quality of your model's adverse scenario performance is as important as its central estimate.
Human expertise, augmentation, and operational risk management
With robust models in place, understanding the human-technology interplay is crucial to successful risk governance. One of the most important clarifications any risk manager should internalize is that machine learning does not replace expert judgment; it scales and standardizes the inputs that feed into it. This distinction matters both operationally and in conversations with your board and regulators.
In practice, ML models handle the heavy lifting of pattern recognition, data processing, and initial risk scoring across large portfolios. Human risk professionals then apply judgment to the model's outputs, particularly in edge cases, novel credit situations, or where regulatory expectations require a documented human decision. As one practitioner-oriented analysis on Medium notes, [AI and ML workflows] are positioned as augmentation to human expert processes, improving scalability and consistency rather than serving as a full replacement for risk judgment.
"AI/ML is positioned as an augmentation to human expert processes, to improve scalability and consistency, rather than a full replacement of risk judgment."
This framing is critical for institutions pursuing automated risk management programs. Automation is not the goal in itself. The goal is freeing your risk team from repetitive, low-judgment tasks so they can focus on the decisions that require experience, contextual knowledge, and regulatory defensibility. ML handles volume; your experts handle complexity.
When structured correctly, ML augmentation also improves the consistency of risk self-assessments in operational risk governance. Institutions that rely entirely on manual scoring of operational risks across business lines often find wide variance in how risk levels are defined and recorded. ML can standardize those inputs, flag inconsistencies, and surface scoring anomalies for human review. This is precisely the kind of workflow enhancement described in AI integration in ERM frameworks that leading institutions are now adopting. When paired with AI risk management strategies, this augmentation layer becomes a significant competitive advantage in both accuracy and regulatory readiness.
Explainability, validation, and governance: Regulatory expectations
With ML augmenting human judgment, governance and regulatory compliance become essential pillars of any responsible deployment. Regulators globally are increasingly clear on their expectations: machine learning models used in risk assessment must meet the same validation, audit, and governance standards as any other internal model, with additional scrutiny applied precisely because of their greater complexity.
The BIS Financial Stability Institute has stated directly that ML-based risk models must be explainable, validated, and governed like other internal models, with heightened expectations due to complexity. This means your institution cannot simply deploy an XGBoost model, observe strong backtesting results, and consider the matter closed. You must document how the model generates its predictions, demonstrate that those predictions are stable across time and conditions, and provide an independent review of its performance.
Frontiers research on AI's role in credit risk also identifies model risk considerations that governance frameworks must address, including interpretability and explainability needs, overfitting risk, stability under changing conditions, and the requirement for independent validation and audit.
The practical implications for your governance structure include:
- Model documentation: Every ML model used in risk decisions must have a written model card describing its training data, architecture, assumptions, and limitations.
- Independent validation: A second-line function must review the model's methodology and performance, separate from the team that built it.
- Bias testing: The model must be tested across protected borrower classes to confirm it does not produce systematically unfavorable outcomes.
- Ongoing performance monitoring: Governance does not end at deployment. Models must be tracked against predefined performance thresholds and recalibrated when those thresholds are breached.
Pro Tip: Establish a model inventory that includes all ML models used in risk assessment, with scheduled review dates and escalation triggers for performance degradation. Regulators increasingly expect this as standard practice, and institutions without it face examination findings.
Following risk management best practices in this area is not just about regulatory compliance. It is about building institutional confidence in the model outputs that drive major credit and capital decisions. The AI-driven risk insights your models generate are only as valuable as the governance framework that validates them.
Limitations, edge cases, and practical deployment tips
Finally, let's confront the real-world challenges and consider how to deploy ML responsibly in risk assessment. No technology delivers uniform value in every scenario, and machine learning is no exception. Understanding where ML models are most likely to underperform is as important as recognizing where they excel.
The Springer Nature study on credit risk classification identified specific deployment edge cases where ML models struggle: distribution shift caused by macroeconomic regime changes, insufficient or biased training data, and reliance on highly complex models whose explanations are not stable or meaningful to risk stakeholders and regulators. Each of these is a real-world scenario that credit risk managers should plan for explicitly.
Distribution shift is the most insidious challenge. An ML model trained on data from a low-rate, stable-growth environment will have learned patterns that may not hold when rates rise sharply or when credit conditions tighten rapidly. The model's training data simply did not include those dynamics, and the model's predictions will drift without the institution knowing immediately. Frontiers research similarly flags overfitting and stability risks as core model risk concerns that require ongoing monitoring rather than one-time validation.
Practical guidance for responsible ML deployment at financial institutions includes:
- Start with interpretable models: Gradient-boosted trees like XGBoost or random forests offer strong performance with better interpretability than deep neural networks, making them more suitable for regulated environments.
- Monitor population stability: Track the distribution of your model's input variables over time using population stability indexes (PSI) to detect drift before it materially degrades predictions.
- Build adversarial test sets: Construct scenarios that represent conditions not present in your training data, including recession scenarios, sector-specific stress, and interest rate shocks, and evaluate model behavior explicitly.
- Simplify where possible: Regulators and internal stakeholders are more likely to trust and act on outputs from models they understand. Marginal accuracy gains from extremely complex architectures rarely justify the governance burden.
Pro Tip: Stress-test your ML models against macro scenarios that are outside their training distribution at least quarterly. Waiting for performance degradation to appear in live portfolio metrics is too late; by that point, risk decisions have already been made on compromised predictions.
Why risk managers should demand more than accuracy: The real value of machine learning
Stepping beyond technical performance, here is how leading risk managers extract real value from ML. The financial industry tends to anchor on accuracy metrics when evaluating model performance, and understandably so. AUC scores, quantile loss ratios, and F1 statistics are clean, comparable, and easy to communicate to senior leadership. But accuracy alone is an insufficient standard for risk model selection, and treating it as the primary criterion is a mistake we see often.
The institutions that extract the most value from machine learning are the ones that approach it with the same rigor they apply to any critical business process. They demand explainability not because regulators require it, but because they understand that a model whose outputs cannot be explained cannot be reliably acted upon. When a credit decision or a capital allocation rests on a model's prediction, the risk manager needs to know not just what the model said but why it said it, and whether that reasoning holds under the conditions currently facing the institution.
There is also a vendor accountability dimension that too few institutions examine carefully. When evaluating advanced AI tools for risk management, challenge your vendors on model validation processes, bias testing results, and how the model behaves when input distributions shift. Any vendor who responds to those questions with marketing language rather than technical documentation is telling you something important about the product's production readiness.
The real value of machine learning in risk assessment is not found in the performance benchmark. It is found in the combination of predictive accuracy, governance-ready explainability, and the institutional discipline to monitor, validate, and update models continuously. Machine learning must be governed as rigorously as any other risk model. Don't let accuracy overshadow transparency.
Take your risk assessment to the next level with AI-powered solutions
Ready to put theory into practice? The principles covered in this article, from ML performance benchmarks and regulatory governance to human-AI collaboration and edge case management, translate directly into decisions about which tools your institution deploys and how you configure them.
RiskInMind was purpose-built for credit unions, community banks, and lenders that need enterprise-grade risk intelligence without the complexity of building it from scratch. Our AI loan assessment tool and CRE risk predictor deliver real-time, explainable risk scores that meet regulatory validation expectations out of the box. For institutions ready to move beyond spreadsheets and static scorecards, our AI risk management pricing page offers flexible options tailored to your institution's size and risk portfolio. The technology is here; the question is how quickly your team can put it to work.
Frequently asked questions
How does machine learning adapt to new types of risk?
ML models learn from both historical and real-time data, enabling them to recognize emerging risk patterns and update predictions continuously rather than waiting for periodic model recalibration.
What is the main regulatory concern with ML in risk assessment?
The biggest concern is explainability. Regulators require that ML-based risk models justify their predictions, undergo independent validation, and be governed with the same rigor applied to any internal risk model.
Can machine learning fully replace human risk managers?
No. As practitioners confirm, AI and ML in risk workflows are designed to augment human expertise by scaling and standardizing assessments, not to substitute the professional judgment that regulatory and governance processes require.
What edge cases should financial institutions watch for in ML models?
The most critical edge cases involve distribution shift, biased data, and models with unstable or non-meaningful explanations, all of which can cause ML predictions to degrade precisely when reliable risk intelligence is most needed.